
Social context of decision process
/Our primary motivations for building data analysis solutions are to help with real problems and to make meaningful impacts. Solving a problem is all about decisions, sometimes a single big one, often a sequence of small steps leading to a preferable outcome. Data analysis software should help make better decisions, based on available data, in a timely manner and using natural experience. Some problems are isolated and solving them requires an individual exploration of vast data spaces – by a single user and with a single set of needs, requirements and preferences. However, in our digital reality, this is rarely the case in practice, as decision making processes usually occur in a social context. That context is based on a social structure of individuals (involved in solving a problem or affected by the solution), but it also includes other components like data sources, available analysis methods and, more and more often, intelligent agents that can actively participate in the decision process.
The relevance of a social context in decision making is the most visible in healthcare, which is currently going through a digital revolution. With all new data that can be processed and the application of advanced algorithms, healthcare is becoming more data-driven at all stages, including disease prevention, diagnosis and treatment. Different forms of data analysis improve the effectiveness and efficiency of decision processes and become key foundations for the next generations of health care. But with successful automation of specific tasks the importance of human elements only increases. There is obviously a focus on the patient, as health care becomes more personalized, with customization of a process and of the medications (pharmacogenomics). A lot of attention is also given to physicians, due to complexity and non-deterministic nature of this domain and the very high potential cost of an error. But it is still not enough, as success in health care critically depends on partnerships and collaborative relationships.
Social context in health care is built upon the relationship between patients and physicians. These relationships are no longer 1-to-1, nor symmetrical, as social structures on both sides usually include multiple participants. On the patient’s side, this is primarily a social network providing support and influence with dynamics that can get easily complex, especially in scenarios when patients cannot take control over their health (e.g. children or elderly persons). On the physician’s side, there is a virtual team of medical professionals working with the patient; the physician should be the trusted point of contact, but the process can now expand beyond the knowledge and experience of any individual. Social context in health care is unique - for example we may assume that all participants in the decision process share the same goal, i.e. well-being of the patient. But this means that there are also unique functional requirements for these relationships to work: they must be designed for a long term, simple and convenient on a daily basis, when there are no major problems, but also efficient and natural in case of a serious medical condition or an emergency.
Figure 1 includes a simple social structure built around the traditional relationship between a patient and a physician as its core. This is just a proof of concept, but similar models for real case studies can be created in various ways: defined a priori (e.g. by roles in a team), constructed based on provided information (e.g. key actors), or automatically generated using records of interactions.

Figure 1. An example of a social structure from a context of decision processes in health care
The models for actual social structures and contexts are obviously dynamic and specific to a situation. That, in addition to possible complexity, makes the functional requirements for the quality of the relationships very hard to meet. In order to be successful in domains likes healthcare, technology must be designed and implemented for the social contexts of their applications. This starts with strong generic fundamentals like secure and reliable data processing, natural experiences, or smooth integration with external components. But this is only the beginning if we want to facilitate efficient cooperation (which can be more important than actual data analysis itself), enable building trust and partnership or help with challenges, emotional factors (e.g. fear) and certain behaviors (e.g. avoidance). Such scenarios require a functionality of relationship management, what means that social context must be taken into consideration at each and every stage of creating software - this is no longer another feature, but rather it becomes one of the core fundamentals.
Let’s take a brief look at the seemingly straightforward requirement of keeping participants of a decision process informed. This means, among other things, that the results of data analysis must be useful for the user. However, with a social context, we have multiple users, with individual needs, requirements and preferences. Each of them needs a different type of story - even the same information should be presented differently to a physician (all the details with analysis decision support) and to a patient (explanations with option of learning more or starting a conversation). One of the features we’re developing in our framework is designed to provide personalized views of shared data space to multiple users and roles of a social structure (for example a company). Personalized user experience is based on individual preferences, but also on analysis of the user’s role, profile (e.g. age for accessibility), the nature of the task/scenario as well as any situational requirements (e.g. pressure due to an emergency). Figure 2 shows possible functional templates of personalized user experience for key users in our example.

Figure 2. Personalized user experiences in a social structure of decision processes in health care
In this post, we used healthcare as the application domain. In this domain, we can see that technology has the potential to improve existing processes and practices but, at the same time, it will change them dramatically. Modern data analysis solutions will not replace physicians, but they will change behavioral patterns of interactions between patients and physicians (and likely beyond). Obviously, healthcare is about people and relationships more than other domains are. But since social context is so essential for our decision processes, we may expect similar changes in other domains affected by democratization of data analysis. Data analysis is becoming social following the path from data connecting users, through natural interactions and cooperation, to relationships focused on very specific challenges. Social contexts will become even more relevant as we start implementing scenarios involving intelligent software agents that can participate in our decision processes. With that change, we are no longer only adapting to a social context, we are actually trying to shape it.
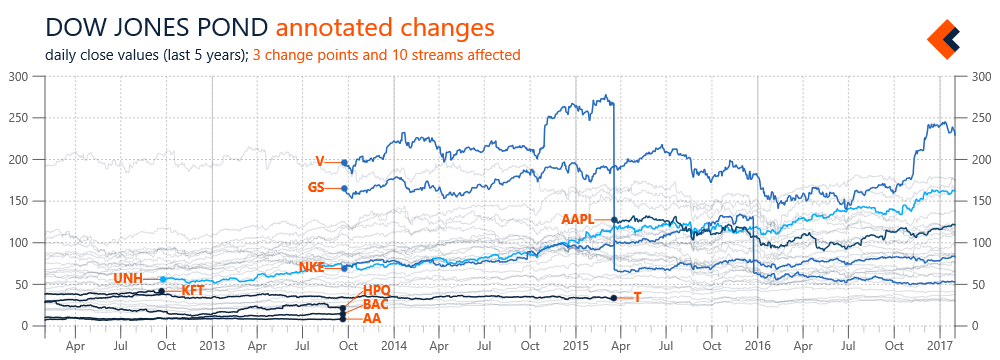


![Figure 2. Dow Jones background with value ranges normalized to [0,1] and Microsoft stock as the foreground (SVG)](https://images.squarespace-cdn.com/content/v1/52e0a367e4b0a7dd7b3beb3f/1481766174416-IHXTSGUSJ8WFTH7WERHI/sw-post09-image02.png)


![Figure 2. Dow Jones components with value ranges normalized to [0,1] and annotation artifact indicating minimum value of average for the whole set (big)](https://images.squarespace-cdn.com/content/v1/52e0a367e4b0a7dd7b3beb3f/1479865650146-LFQOKWZUTG4URJKV8GV8/sw-post08-image02.png)


