
Visual Artifacts in Data Analysis
/It’s difficult to overestimate the value of visualization in data analysis. Visual representations of data should not be considered the results of an analysis process, but rather the essential tools and methods that should be applied at every stage of working with data. When dealing with specific data and questions, we often find it useful to add non-standard visual elements that are adapted to characteristics of the data, goals of analysis tasks or individual and organizational requirements. We refer to such new elements as analysis artifacts, which can be defined as visual products of analysis methods, general or specific for domain and scenario, providing additional context for the results or the analysis process. There may be various goals identified for specific analysis artifacts, but their general role is to make the analysis user experience more accessible, adaptable and available.
Analysis artifacts can take many forms, from text elements, through supplementary data series, to new custom shapes and visual constructs. The simplest example are contextual text annotations, often automatically added, with details regarding the data or the process (see example). Some analysis artifacts are generic as they address data properties, like the cyclical or seasonal nature of a time series, patterns and trends (e.g. rent case study), outliers and anomalies or differences and similarities against population data. Some others are specific for a domain and/or type of an analysis task, and may be closely integrated with methods implemented in related analysis templates. In practice, we can think about different types of analysis artifacts in terms of tasks used in analysis decision support:
- SUMMARIZE the structure and quality of data, results of analysis or execution of the process
- EXPLAIN applied analysis methods, identified patterns, trends or other interesting discoveries
- GUIDE through the next available and recommended steps at given point of the analysis process
- INTEGRATE the data from different sources and the results from different methods and agents
- RELATE the results, data points, data series, big picture context, and input from different users
- EXPLORE anomalies, changes, hypothesizes and opportunities for experimentation or side questions
Figure 1 includes an example of domain and scenario specific analysis artifact (INTEGRATE type) for stock market transactions. This artifact illustrates a single purchase of stock and subsequent sales, using historical quotes as the background. For each sale event, the information about number of sold stock, their value and gain/loss are included.

Figure 1. Analysis artifact for stock transactions, with a single purchase and multiple sales events (SVG)
Analysis artifacts can be considered means for adaptation of analysis experience to the context of analysis tasks and user’s needs, requirements and preferences. They can be highly customized and personalized, leading to adaptive user experiences that are more effective and efficient in the scope of controlling the analysis processes and interpreting the results. These capabilities make analysis artifacts very powerful tools for complex decision problems and situations. They can be very useful in dealing with imperfect data, potential information overflow, operating under strong external requirements (e.g. time constraints) or in configurations with multiple participants and incompatible goals and priorities. We found that they can be also helpful beyond visualization, as the artifact-related data structures can become subjects of analysis or be applied in a completely different scope or a different scenario.
For example, Figure 2 presents a simple simulation based on the analysis artifact presented in Figure 1. The data structure related to that artifact are used here to illustrate a hypothetical scenario of investing the same amount of money in a different stock and following the same exact sales schedule (selling the same percentage of stock at each time point).
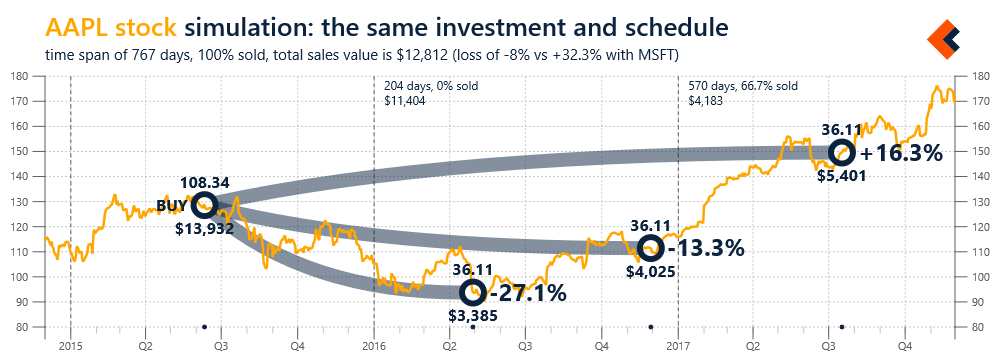
We think about visualization of our data as merely a canvas upon which we can paint specialized and personalized artifacts from our analysis processes. These artifacts can be applied not only in the scope of individual charts, but also for interactive decision workflows, based on multiple data sources, that may require many integrated visualizations in order to provide a sufficient context for a decision maker. This is especially important for data analysis in social context, with advanced collaboration scenarios involving multiple human participants and AI agents. As the complexity of algorithms and models is increasing, we need to provide significantly more user-friendly analysis environments for expanding number and variety of users. Multimodal interactions and technologies for virtual or mixed reality have great potential, but the best way to deal with complexity is to focus on simplicity. Analysis artifacts seem to be natural approach to that challenge and they should lead us to brand new types of data analysis experiences, which may soon be necessities, not just opportunities.







