Threat modeling data analysis processes
/In the previous post, we talked about our data driven decision processes taking place in socio-technical systems and becoming more dependent on the results from data analysis solutions. These underlying technical solutions can be attacked in order to disrupt the decision processes, including changing their outcomes. In order to have confidence in data driven decision-making, we need to understand the threats that the underlying data analysis processes are facing. Fortunately, we can use experience from information and software security to do that.
Most security problems result from complexity, unverified assumptions and/or dependencies on external entities. We need to understand the system, in order to protect it. This is a common problem in information and software security. We use threat modeling methodologies to evaluate the design of an information processing system in the security context. We look at the system from the attackers’ POV and try to find ways in which security properties, like confidentiality, integrity or availability could be compromised. The resultant threat model includes a list of enumerated threats, e.g. using a format like "an adversary performs action A in order to achieve a specific goal X”. We look at each of these threats and check if it is mitigated. If a mitigation is missing or incomplete, we can talk about a potential design vulnerability. We can apply the same approach to the socio-technical systems used in data driven decision processes.
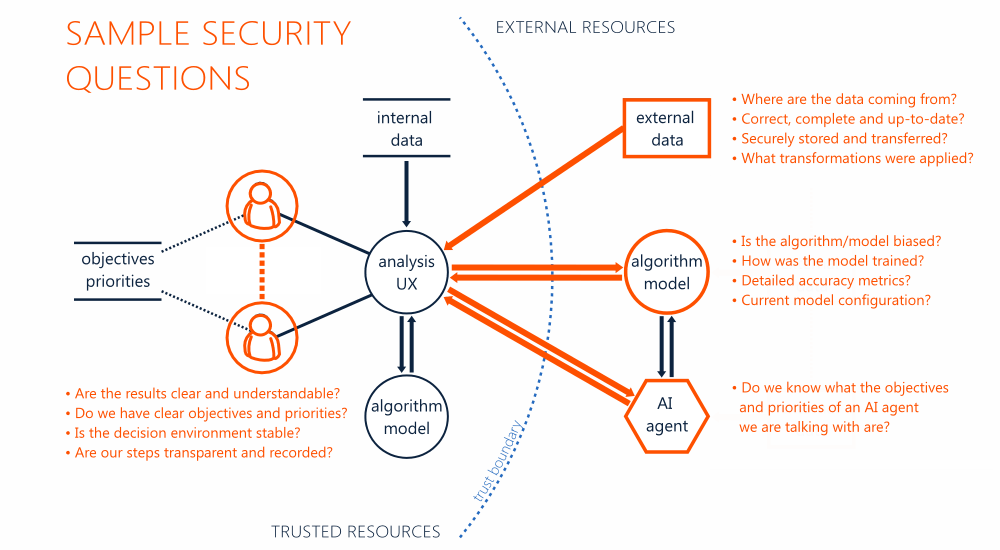
This is actually what we started to do in the previous post, when we were asking questions about entry points to our system, its dependencies and the related assumptions. Below we will briefly discuss possible mitigations, which can be technical, but can also be organizational or legal. Figure 1 includes the same model of a socio-technical system as in the previous post, but this time with examples of mitigations related to the critical components.

Figure 1. A model of a socio-technical system in a decision-making with examples of possible mitigations.
We know mitigations for generic threats (e.g. how to store and transfer data securely), however mitigations for threats related to data analysis scenarios still need to be researched.
- In the scope of external data sources, we want to know where the data are coming form, what transformation were applied or how missing values or outliers were handled. We can apply data quality metrics and techniques to verify data origin, but there are still scenarios that will be more difficult, for example when data are contributed by many anonymous users.
- In case of algorithms and models, we might need information like accuracy metrics, full configurations or summaries of training and test data sets. We may periodically test the models or evaluate the results from different providers. Still, in some cases, independent certifications or specific service level agreements, covering also analysis objectives and priorities, may be required.
- Decision makers can be protected with user experiences designed for decision making scenarios (including domain characteristics or situational requirements). These are great opportunities for analysis or visual decision support. We need to be careful with new types of interfaces, like augmented reality, as they will be connected with new types of threats against our cognitive abilities.
- New types of threats will also emerge from integration with AI agents in decision contexts. We don’t know yet the detailed applications, however we can already think about some potential mitigations focused on measuring, analysis and controlling interactions. There are types of threats, like repudiation, that will likely be much more important in such cooperation scenarios.
In order to have confidence in data driven decisions, we need to design our processes to be reliable, trustworthy and resistant to attacks. This requires good understanding of goals and assets of our decision-making; based on that we can specify requirements for underlying data analysis and make informed decisions about selecting specific data sources and analysis components. Threat modeling can be a great tool for that, but the methodologies must be adapted to the nature of socio-technical systems, which can be very dynamic and hard to model. But there can also be new opportunities, as we could define new requirements related, for example, to transparency, accountability or independence. These requirements could be very useful for decisions with broad social impact or shared goals, which had to be agreed to between multiple parties.
Security efforts are continuous in their nature. New technologies enable new scenarios, leading to new threats, which may require new or updated mitigations. We need to continuously think about threats and cannot focus only on the opportunities and benefits of new technologies and applications. If we do, we may soon find our decision processes to be very effective and accurate, but no longer compatible with our goals and priorities.
This series of posts is based on the presentation made during Bloomberg Data for Good Exchange Conference, on September 24th 2017 (paper, slides).